Notes
This is where I write down my random daily thoughts, my weekly learnings, goals, plans etc.

Starting the weekly review
Last updated: March 16, 2025
First week review
It’s been three weeks since I started this blog. I was so excited to post about anything and everything … writing about what I learned, what I plan to learn, and sharing my experiences on various topics.
But here I am, paralyzed by the need to make everything “perfect.”
This kind of thinking keeps recurring in my life, stopping me from doing the things I truly want to do. Mostly, it’s because I fear doing it wrong or not having enough to talk about (even though I’ve already written a list of dozens of topics I could write about).
I feel like I don’t know how to start this..
But guess what? I’ll never know unless I give it a shot. A first start, just one tiny step.
So, on the night of March 16th (also the 16th of Ramadan), I decided: “Hey, let’s write the first weekly update.”
I’ve always wanted to have a blog to write about tech and my learning journey.
One of the things I’ve wanted to do most is weekly learning updates — basically, writing about what I did during the week in a nutshell, focusing on the learning aspects, the obstacles I faced, and how I can improve.
I was inspired by various blogs, like Ali Abdaal’s weekly life notes.
So, let’s get started!
Reflecting on the First Quarter Goals
Last week, I reviewed my progress on my first-quarter goals and realized a few things:
-
Lack of Daily Monitoring: Sometimes, I set weekly goals and try to break them into daily tasks, but this wasn’t efficient. I wasn’t tracking my habits, time, or daily accomplishments—especially with the start of Ramadan and the change in schedule. Time just flies by.
So, this week, I started doing daily reviews and writing down the details of my day.
-
Destroying Perfectionism: I need to adopt a “Bad First Draft” mentality. And here we are, doing just that.
-
Slow Progress on ML Course: It’s been months since I started the ML specialization course, but my progress has been super slow due to inconsistency.
What I did: I reintroduced the ML course as a daily habit (20 minutes every day). And guess what? I finally finished the unit I was stuck on!
My mission for this week was: “Keep the Momentum Alive.”
What I Did This Week
1. Neural Networks Deep Dive
I tried to tackle neural networks and get a deeper understanding of them. Last year, I started learning about ML, DL, and LLMs for my Bachelor’s final project, but I realized there were many gaps in my knowledge. This became clear during a college module called “Machine Learning and Neural Networks.”
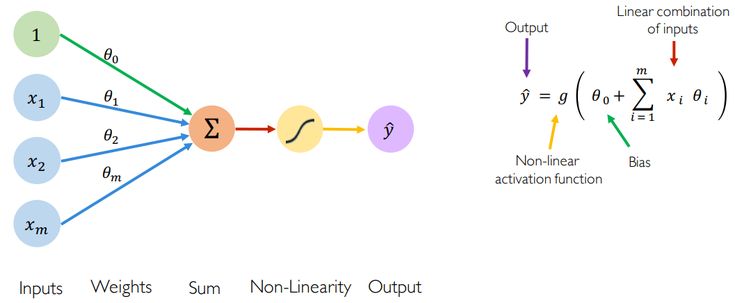
I read a few articles on backpropagation and NNs:
Along with that, I practiced implementing neural networks.
2. Spirituality and Islam
I took notes on two videos about Ramadan and CHANGE by Ahmed Abd al Monim. They were very useful and served as fuel for the start of the week:
3. Game Design Document
I created a Game Design Document for my college module, “CJRV: Game Development and Virtual Reality.”
It was challenging to think of how to design a game with limited VR aspects, but it was fun diving into this.
It’s literally my beginning in game development.
(PS: Stay tuned for me learning Blender and Unity!)
4. College TPs
Some days this week, I felt super unmotivated to attend college TPs (practical work sessions). I skipped some, not gonna lie, while focusing on others. I’m not sure if this was a good idea, but I was certainly overwhelmed. (To give you context, we have 7 TPs — not trying to make excuses, but yeah, I am.)
5. Energy and Time Management
It was hard to balance my energy this week, especially with sleeping and learning times. Most of the week went into college homework.
6. Data Mining TP
I worked on a Data Mining TP, which was like a mini-research project. We tried to improve the Apriori Algorithm. I mainly used statistical methods and evaluation metrics, which the professor liked. (Phew! He’s a very precise prof.)
7. Group Reading Sessions
I spent a good amount of time this week on group reading sessions for Muqaddimah Ibn Khaldun (مقدّمة ابن خلدون). I was invested on these sessions, though I feel some guilt because they take up more time than I’d like.
8. Weekend Slackiness
I realized that the last two weekends, I’ve been super slacky. But I guess it’s good sometimes to focus only on family during weekends.
9. Reading Al-Naba’ Al-Adheem (النبأ العظيم)
I started reading a book on the greatness of the Quran called Al-Naba’ Al-Adheem. Since this is the month of Ramadan, it’s a great time to listen to Tafseer and learn more about the Quran.
Big Takeaway of the Week
📛 All types of actions carry momentum. It can be good or bad.
Though this week was full of things, I do realize I need more delibrate work specially on the technical aspect .

Starting the learning challenge!
Last updated: September 17, 2025
| # Day 1 | Momentum Learning Series |
This blog marks the start of a personal challenge: a series where I commit to learning every single day and documenting it here. My focus is on computer science, AI, and computer vision. The rule is simple: at least one hour of learning a day, and one honest reflection written down. You can join me in this challenge too — build consistency, learn something daily, and record it.
This summer my focus was on AI agents and deepening more into computer vision.
And today I finished the last part of a course I started earlier, which was about LLMOps automating and monitoring all steps of ML system construction (LLM development and managing the model in production). In the course we studied data preparation, automation, and orchestration with pipelines (which for me was the essential part of the course). And lastly, what I studied today: prediction, prompts, and safety. It was about deploying the model via REST API, then unpacking and formatting data, and a quick scope on Safety Attributes. The short course was informative, but I could’ve studied it in a shorter time, like in one session.
Then, I studied from the book Deep Learning for Computer Vision Systems, which I also started this summer, because I felt studying computer vision needs a stronger theoretical side, so this was a good resource for me. I started chapter 3 on CNNs, and how image classification using MLPs has its drawbacks by doing an image classification with the MNIST dataset using a very simple neural network. The key lesson was how NNs need the input image to be flattened from a 2D matrix into a 1D vector, and by this process we lose spatial features, which makes the training on finding patterns of close areas in the image harder and take longer. Whereas in CNNs there are convolutional layers, where each neuron is connected only to a small local region of the image instead of all pixels as in MLPs.
This book is a great revision for some fundamentals in CV and DL, and it’s really good at capturing and connecting every piece of information together.
Good Tip: Always check whether the technique you’re learning (like flattening inputs) is a simplification or a limitation, sometimes the most important lesson is why a method fails.
—>
Momentum Learning Day 2
Last updated: September 18, 2025
| # Day 2 | Momentum Learning Series |
To strengthen and deepen my knowledge of agents, I started a new course called LLMs as Operating Systems: Agent Memory.
It introduces the idea of self-editable memory in agents, with a focus on the MemGPT design.
The key concept is that the context input window can be thought of as a kind of virtual memory in a computer, where the LLM agent also plays the role of an operating system deciding which information should go into the input context window.
As practice, I built a simple agent with editable memory from scratch, using only a Python dictionary as the memory.
I then designed a function to update this memory when needed, and instructed the LLM (OpenAI in this case) on how to use the tool (the “function”).
The most important part was creating an agentic loop, so the agent could perform multi-step reasoning as required.
This felt like working at a low-level foundation something I can build on later to create more complex agents with memory.
Book part
After that, I studied from the Deep Learning for Computer Vision book. I reviewed how, in image classification, MLPs (fully connected layers) struggled with feature learning from images.
This is why CNNs replaced them for feature extraction, while fully connected layers remain useful for the classification stage.
The high-level CNN architecture looks like this:
- Input layer
- Convolutional layers (for feature extraction)
- Fully connected layer (for classification)
- Output prediction
The convolutional layers produce feature maps of the image. With each layer, the image dimensions shrink while the depth increases, until we end up with a long array of small features. These are then fed into the fully connected layer for classification.
In terms of feature learning:
- Early layers detect low-level features such as lines and edges.
- Later layers detect patterns within patterns, gradually learning more complex features until the model captures the bigger picture.
Momentum Learning Day 3
Last updated: September 19, 2025
| # Day 3 | Momentum Learning Series |
Today I studied just a little, but I kept the streak alive.
I went through MemGPT (arxiv: 2310.08560), along with the course LLMs as Operating Systems: Agent Memory.
Key Ideas
- The context window holds the most important information.
- Archival memory → for general-purpose data.
- Recall memory → for old message history.
- Both archival and recall memory keep statistics for tracking and management.
Small step, but progress is progress.
💡 Note to myself: studying in the morning works best. Don’t push it to late afternoons, finish it as early as possible.
Momentum Learning Day 4
Last updated: September 20, 2025
| # Day 4 | Momentum Learning Series |
Today I went deeper into how memory works inside Letta agents.
I set up a simple agent with two blocks (one for human input and one for persona ) and played around with inspecting its system prompt, tools, and memory history. It was nice to actually see how the agent keeps track of things behind the scenes.
The main idea was the difference between core memory (what the agent actively uses in context) and archival memory (stuff saved for later but not in the immediate window). That split makes a lot of sense once you see it in action.
I also tried customizing memory: adding new blocks and tools, and even building a small task queue memory where the agent can push and pop tasks.
That part was fun, it felt like giving the agent a basic to-do list that it can manage on its own.
What I liked most is how programmable the memory system is. It’s not just the model doing black-box reasoning; you can shape how it remembers and interacts with information. As an engineer, that feels powerful.. it opens up room for building agents that aren’t only “smart,” but also structured and adaptable.
PS: I haven’t studied the CV book for two days. Tomorrow I need to catch up inchallah and also finish this course!
Momentum Learning Day 5
Last updated: September 21, 2025
| # Day 5 | Momentum Learning Series |
Today I wrapped up the LLMs as Operating Systems course. It feels like a milestone because now I see the bigger picture of how LLMs can actually work as the “core” of applications, not just a chatbot.
Agentic RAG & External Memory
The main takeaway was about giving agents memory and data sources:
- One way is just copying data into their archival memory (like a built-in database the agent can look up).
- The other way is connecting the agent to an external tool that can query data on demand.
I tested both:
- Created a source (“employee handbook”), uploaded a file, attached it to the agent, and made sure embeddings matched. Once connected, the agent could reference the file like it had read it itself.
- Then I built a dummy “database” (just a dictionary) and plugged it into the agent via a tool. The agent could call this tool and fetch answers from it.
From an engineer’s perspective, this makes things more modular. Instead of cramming everything into the context window, we can design agents that reach out for information.
Multi-Agent Orchestration
The second part was about getting multiple agents to collaborate. In Letta, agents are meant to run as services, so the question is: how do they talk to each other?
There are two ways:
- Message tools → one agent can send a message to another.
- Shared memory blocks → two agents share the same context window so they both “see” the same data.
I built two agents:
- One for outreach (like sending resumes).
- Another for evaluation (with a reject/approve tool).
They passed messages back and forth, and with shared memory, both had the same view of what was going on.
Finally, I tried the multi-agent abstraction: put both agents into a single group chat. That was simpler, but the idea is the same agents can coordinate either by tools or by a shared space.
For me, this part really shows how we can move beyond a single “all knowing” agent. We can design specialized agents that cooperate almost like microservices, but in natural language.
Reflection
I’ll be honest: I rushed through today to keep up with the consistency streak. I didn’t touch the CV book again, and I know I need to fix my timing so I’m not just checking boxes but actually digesting the material.
Still, I’m happy I finished the course, it gave me a clear technical intuition about how LLM-based systems are structured:
- Memory is not just a bigger context window, but a system of archives and tools.
- Agents can be extended and composed, almost like APIs calling each other.
That’s powerful to know as an engineer. Inchallah, tomorrow I’ll slow down a bit, return to the CV book, and balance the depth with consistency.
Momentum Learning Day 6
Last updated: September 22, 2025
| # Day 6 | Momentum Learning Series |
After finishing the LLMs as Operating Systems course yesterday, I didn’t want to lose momentum, but I also didn’t want to just rush into something shiny and new.
So today was about reinforcing foundations while continuing the bigger plan I set for myself around agents.
Revisiting CNNs
I went back to the deep learning for computer vision book and re-read the CNN chapters. I already know CNNs, but coming back to them with an engineer’s mindset feels different than just “studying the theory.”
When you look at CNNs in the context of building CV systems, the design choices really stand out:
- Convolutional layers → not just math, but a way to force the network to learn local patterns.
- Pooling layers → a clever compression trick: you don’t need every pixel, just the essence.
- Fully connected layers → the collapse point, where the network finally says: alright, classify this thing already.
The beauty here is constraints leading to elegance.
A kernel is tiny — just a 3×3 or 5×5 matrix of weights — but sliding it across an image extracts edges, textures, and higher-level features.
That minimal design is why CNNs became the backbone of modern vision, and why they still matter even when transformers dominate the headlines.
So no, this wasn’t new learning.
It was sharpening a tool I know I’ll need later in this CV book.
HuggingFace Agents and Picking Up the Plan
The second thread today was getting back to the AI Agents course from HuggingFace, specifically the Smolagents framework.
This is something I had started in the summer but left unfinished.
Picking it up now iq part of the roadmap.
What stood out about Smolagents:
- Code-first → you don’t just prompt and hope; you define actions in code.
- Lightweight → minimal abstraction, fast experiments.
- Flexible → HuggingFace Hub + multiple LLMs supported out of the box.
It supports:
- CodeAgents (the core type).
- ToolCallingAgents (via JSON).
- Multi-step workflows → chain actions together.
Compared to yesterday’s look at Letta and multi-agent orchestration, Smolagents feels like the sandbox where I can actually get my hands dirty, test ideas, and learn fast.
Reflection
Day 6 wasn’t about breakthroughs, it was about engineering discipline:
- Revisiting CNNs → reinforced why their design still matters in CV.
- Smolagents → gave me a lightweight, practical entry point for agents.
If Day 5 was about seeing the architecture,
Day 6 was about picking the right tools off the shelf and checking they’re sharp.
Momentum Learning Day 7
Last updated: September 23, 2025
| # Day 7 | Momentum Learning Series |
Today I got deeper into smolagents, specifically the CodeAgent.
The core insight: letting the agent write and execute Python code instead of just JSON unlocks flexibility and makes tool use feel natural.
In practice, this means you don’t just get a black-box answer. You see:
- the Python code the model generated,
- the execution results,
- and the reasoning steps logged in memory.
For me, that transparency was the big shift. It felt less like guessing and more like debugging with a colleague.
What I Built: Alfred the Party Planner 🦇
I followed the tutorial and built a playful butler agent (Alfred) that plans a party at Wayne’s mansion.
- Custom tools I wrote:
suggest_menu(): suggest menus depending on the occasion.catering_service_tool(): simulate picking the best catering service in Gotham.SuperheroPartyThemeTool: generate themed ideas .
- Prebuilt tools I plugged in:
DuckDuckGoSearchTool(search),VisitWebpageTool(navigate),FinalAnswerTool(format output).
With these wired into a CodeAgent, I could ask:
“Give me the best playlist for a party at Wayne’s mansion. Theme: villain masquerade.”
Alfred went step by step: picked the theme, searched, browsed links, and finally returned a curated playlist.
Watching each tool call and execution log made the whole process feel robust and traceable.
Reflections as an Engineer
- smolagents is pragmatic: the
MultiStepAgent+ execution log design is exactly what makes debugging feasible. - Small tools matter: even trivial ones (
suggest_menu) gave structure and extended capabilities. - Observability is real: I like that smolagents integrates with OpenTelemetry + Langfuse. Being able to replay a run or see why it failed is non-negotiable in production.
- Feels future-proof: this setup makes agents composable, testable, and closer to real software systems rather than “magic prompts.”
Next Step
The party planner was fun, but the same pattern applies to serious workflows.
Next, I want to try building a study assistant that schedules prep tasks with [datetime] and pushes runs to the Hugging Face Hub for reuse.
End of Day 7. I feel like I’m not just learning AI concepts anymore, I’m actually starting to think like an engineer of agents.
Momentum Learning Day 8
Last updated: September 24, 2025
Day 8 | Momentum Learning Series
Today I dug into the difference between CodeAgent and ToolCallingAgent in smolagents.
The key learning is that CodeAgent generates Python code while ToolCallingAgent outputs JSON blobs with tool names and arguments.
That shift in representation really matters:
- With Python, I get flexibility and the ability to debug by reading the generated code.
- With JSON, I get structure and predictability, which feels closer to API wiring.
Even the traces highlight this difference, a CodeAgent shows “Executing parsed code …” while a ToolCallingAgent shows “Calling tool … with arguments …”. Seeing that contrast made me realize how the action format shapes both observability and debugging flow.
To practice, I extended my “party planner” agent Alfred using both methods.
With the @tool decorator, I built a quick catering_service_tool() to simulate picking the best catering in Gotham.
With the subclass method, I wrote SuperheroPartyThemeTool, where I explicitly defined inputs, outputs, and a forward function.
This hands-on contrast made it clear:
- The decorator path is perfect for quick prototyping.
- The subclass path forces more structure, which scales better for complex systems.
Writing these tools also taught me that designing them is basically API design!! I had to be deliberate with names, argument types, and descriptions, otherwise the agent reasoning would get messy. That clicked as a very software engineering way of thinking about AI.
By the end of today, I see the tradeoff clearly: JSON calls give clean structure, Python execution gives expressive power. Choosing one is less about “which is better” and more about “what the workflow needs.”
That mindset shift felt like moving from “using AI” to actually engineering orchestration layers between reasoning and execution.
End of Day 8. My biggest takeaway: how actions are represented code vs JSON changes everything about how the agent behaves and how I interact with it as an engineer.
Momentum Learning Day 9
Last updated: September 29, 2025
Day 9 | Momentum Learning Series
After four days away, I came back to the course today. Pausing was a useful reminder: momentum is fragile, but once the concepts have been internalized, resuming feels less like starting over and more like reconnecting with a system already in place.
The Agents course is still long, but I’m steadily moving through it , aiming to complete the smolagents section tomorrow inchallah.
Retrieval Agents
Today’s focus was on Retrieval-Augmented Generation (RAG) and its agentic extension.
- Traditional RAG: simply retrieval + generation.
- Agentic RAG: retrieval becomes iterative and reflective. Agents can formulate queries, evaluate results, and loop until a satisfying outcome is reached.
This shift made me see retrieval not as a static lookup, but as a reasoning layer tightly integrated with the agent’s decision cycle.
What I Implemented
- Web Search Agent with DDGS
- Used
CodeAgentwithDuckDuckGoSearchTool. - Flow: analyze request → retrieve → process → store for reuse.
- This embedded retrieval directly inside the reasoning process, rather than treating it as a side operation.
- Used
- Custom Knowledge Base with BM25Retriever
- Built a small knowledge set (superhero party themes).
- Applied a text splitter, then designed
PartyPlanningRetrieverToolwith BM25 to return top 5 ranked results. - Engineering perspective: constructing a pipeline — raw docs → embeddings/index → retriever → agent reasoning.
Embedded Reflections
- Building tools felt less like “trying out features” and more like designing interfaces for agents to reason over knowledge.
- BM25 gave precise ranking control, showing that retrieval quality is deeply tied to algorithmic choice, not just embeddings.
- Compared to earlier exercises, today’s work had more of a system-architecture feel: retrieval pipelines as part of the reasoning flow, not isolated utilities.
Quiz Checkpoints
- Tool Creation → lightweight functions via
@tool; complex ones viaToolsubclasses. - CodeAgent & ReAct → iterative cycle of reasoning, action, feedback, adjustment.
- Tool Sharing → Hugging Face Hub makes custom tools reusable across projects.
- ToolCallingAgent → emits JSON with tool + arguments.
- Default Toolbox → provides baseline tools (search, Python, etc.) for prototyping.
Takeaway: Retrieval isn’t passive storage or search; it’s an active reasoning partner in agent workflows. And even with long gaps, progress compounds: the deeper the system level understanding, the quicker I can pick up where I left off.
At this point, it’s less about learning a course and more about shaping the mindset of an agent systems architect, designing the reasoning flow itself, not just calling tools.